Introduction
Synesthesia and consistency testing
Within synesthesia research, consistency tests are often used. Basically, a participant is presented a set of stimuli (inducers; e. g. letters, digits, months) and has to respond by indicating what color (concurrent), if any, they associate with the grapheme. Each stimulus is repeated a certain number of times, usually three times, throughout the test. If the participant is unusually consistent in the colors they respond with, e. g. choosing a red color every time an ‘A’ is shown and always choosing a green color for ‘H’, this indicates that the participant might have synesthetic grapheme-color associations. There might of course be other reasons for consistent response patterns, such as if the participant employed mnemonic strategies, for which reason consistency testing is often combined with other measures for synesthesia classification. Still, consistency testing is widely considered to be an important tool for synesthesia research.
An archetypal form of synesthesia, often investigated with consistency tests, is grapheme-color synesthesia, where grapheme refers to a single written symbol such as a digit or a letter. Note that in order to make the documentation less abstract, synr’s documentation and code consistently uses ‘grapheme’ to refer to consistency test stimuli in general. Examples of this can be seen below. Note, however, that synr can be also be used with data from consistency tests involving non-grapheme stimuli (an example of this can be found in another synr vignette available online).
In consistency testing, participants’ levels of consistency are estimated by using a score based on response colors’ color space distances. This has been called by different names, such as ‘color variation score’. Within the synr package, the term ‘consistency score’ is used to refer to this score.
synr’s purpose
The aim of this package is to facilitate analysis of consistency test data by providing functionality for rolling all the consistency test data up into one specialized R object. This object, with its linked methods (functions), constitutes an effective interface for:
- Quick access/lookup of individual participants’ data.
- Calculation of consistency scores.
- Since different researchers have used different color spaces to calculate consistency scores, methods include options for specifying some (but not all) different color spaces.
- Similarly, different algorithms (e. g. manhattan distance or Euclidean distance) have been utilized to calculate color space distances. synr allows for choosing between some options here also, through specifications in method calls.
- Validating participant data using so-called clustering.
- This identifies participants who have too few responses or have used too few colors, e. g. only black and white, for their data to be reliable for estimating the degree of synesthetic associations.
- Filtering the data in order to calculate the above statistics only
for a subset of graphemes.
- This helps when trying to identify e. g. participants who have synesthesia for digits, but not other graphemes.
- Simple plotting of individual participants’ data.
- This is useful for quick visual inspection of participant responses. This might aid in double checking procedures for identifying synesthetes or classifying participant data as valid/invalid.
Getting started
Rolling up the data
When using synr, your main interface to the data is the ParticipantGroup class. For information on how to convert raw consistency test data into a ParticipantGroup object, please see the separate tutorial Creating ParticipantGroup objects. Here, it’s assumed that the raw data are in ‘long format’, as briefly shown below:
head(synr_exampledf_long_small)
#> participant_id trial_symbol response_color response_time
#> 1 1 A 23F0BE 1.2
#> 2 1 7 99EECC 3.7
#> 3 1 D 001100 2.5
#> 4 1 D 9788DD 1.7
#> 5 1 A 1348CA 0.9
#> 6 1 7 173EF3 2.0Since the data are in ‘long format’, they can be used with
create_participantgroup like this:
pg <- create_participantgroup(
raw_df=synr_exampledf_long_small,
n_trials_per_grapheme=2,
id_col_name="participant_id",
symbol_col_name="trial_symbol",
color_col_name="response_color",
time_col_name="response_time",
color_space_spec="Luv"
)Once you have a ParticipantGroup object (simply called ‘participantgroup’ from here on), you can start using methods with it and accessing its attributes. synr implements this with reference classes, which is an advanced topic. The idea however is that you can learn through synr’s articles and help documentation how to use the tools without having to worry about how they work under the hood.
Accessing participantgroup data
The participantgroup has a nested structure, where the
participantgroup has a list of
participants, and each participant has a list of
graphemes. By using $ as a separator, you
can specify a participant and/or a grapheme to drill down into this
nested structure and access data or methods you need.
Let’s start by accessing participants’ data. Say you want to find
what colors the participant with ID ‘3’ used for the symbol ‘A’. You can
do this by using the syntax
<participantgroup>$participants[['<ID>']]$graphemes[[<symbol>]].
fetched_grapheme_data <- pg$participants[['3']]$graphemes[['A']]
fetched_grapheme_data
#> Reference class object of class "Grapheme"
#> Field "symbol":
#> [1] "A"
#> Field "response_colors":
#> [,1] [,2] [,3]
#> [1,] 64.41700 -25.894798 66.0961
#> [2,] 33.73906 -2.818399 -123.0723
#> Field "response_times":
#> [1] 9.9 8.1
#> Field "color_space":
#> [1] "Luv"The response colors are represented by an nx3 matrix, where n is the
number of trials per grapheme (2 in this example). Each row corresponds
to one response. The three columns correspond to the dimensions of the
used color space, in this case ‘L’, ‘u’ and ‘v’ (because of the
specification color_space_spec = "Luv" when creating the
participantgroup).
You can access participants by either their row number in the raw
data frame, or by their participant ID. In the example, these happen to
be the same except that one is of type numeric and the other of type
character (the participant on row number 3 of the raw data frame has the
ID ‘3’), so both pg$participants[['3']]$graphemes[['A']]
and pg$participants[[3]]$graphemes[['A']] work. If instead
the third participant had the ID ‘jane’, you could use either
pg$participants[['jane']]$graphemes[['A']] or
pg$participants[[3]]$graphemes[['A']].
Summarizing data
A method is a function that is linked to a particular R object, and
synr relies heavily on methods. The syntax for using methods is
<object>$<method_name>(). The examples below
illustrate this.
Consistency scores
grapheme level: get_consistency_score
You can calculate the consistency score of a single grapheme by:
- Specifying what participant you want from the participantgroup.
- Specifying what grapheme you want from the participant’s list of graphemes.
- Using the grapheme’s method
get_consistency_score.
# fetching the consistency score of the second participant's grapheme 'A'
cscore_p2_A <- pg$participants[[2]]$graphemes[['A']]$get_consistency_score()
cscore_p2_A
#> [1] 76.40256There are many more grapheme-level methods, but you usually only need
the corresponding participant- and participantgroup-level methods. For
this reason, no more examples of grapheme-level methods are provided in
this tutorial; you can instead read the help documentation if you want
(run help(Grapheme)).
participant level: get_mean_consistency_score
You can calculate an individual participant’s mean consistency score by:
- Specifying what participant you want from the participantgroup.
- Calling the participant’s method
get_mean_consistency_score:
mean_cscore_p1 <- pg$participants[['1']]$get_mean_consistency_score()
mean_cscore_p1
#> [1] 131.206participantgroup level:
get_mean_consistency_scores
The participantgroup method get_mean_consistency_scores
calculates the mean consistency scores for all participants, producing a
numeric vector with the consistency scores:
mean_cscores <- pg$get_mean_consistency_scores()
mean_cscores
#> [1] 131.2060 101.3738 151.9597The order of the mean consistency scores is based on the order of participants in the original raw data frame.
To form a data frame that shows which participant goes with which
participant score, the participantgroup method get_ids
comes in handy:
mean_cscores <- pg$get_mean_consistency_scores()
p_ids <- pg$get_ids()
mean_scores_df <- data.frame(participant_id=p_ids, mean_consistency_score=mean_cscores)
mean_scores_df
#> participant_id mean_consistency_score
#> 1 1 131.2060
#> 2 2 101.3738
#> 3 3 151.9597Number of valid responses
It often helps to see how many valid color responses participants have provided during the experiment. It’s common for consistency tests to provide some kind of ‘no color’ response. This is usually provided mainly as a tool for people who do have synesthetic associations to use for non-inducing stimuli, but might be ‘abused’ by people with no synesthetic associations. A mean consistency score is meaningless if a participant has for instance responded with ‘no color’ for all but two graphemes’ responsese, since it’s simple to memorize colors for two symbols.
Note that for synr to work, ‘no color’ responses must be coded as
NA values. For more information about this, please see the
article Creating ParticipantGroup
objects.
participant level:
get_number_all_colored_graphemes
This method returns the number of graphemes that only have non-NA color responses. Thus, if data are from a consistency test with 3 trials/grapheme, the number of graphemes with 3 non-NA responses is returned.
num_onlynonna_p2 <- pg$participants[['2']]$get_number_all_colored_graphemes()
num_onlynonna_p2
#> [1] 3So, the second participant gave only valid (non-NA) color responses for 3 graphemes.
participantgroup level:
get_numbers_all_colored_graphemes
The participantgroup method
get_numbers_all_colored_graphemes produces a numeric vector
that holds each participant’s number of valid color responses:
num_onlynonna <- pg$get_numbers_all_colored_graphemes()
num_onlynonna
#> [1] 3 3 3All three participants gave only valid (non-NA) color responses for 3 graphemes. The values are in the same order that participants were in in the raw data frame, meaning that the first value corresponds to the first participant, and so on.
Of course, you can combine these values with participant ID’s just like we did above with mean consistency scores:
mean_cscores <- pg$get_mean_consistency_scores()
num_onlynonna <- pg$get_numbers_all_colored_graphemes()
p_ids <- pg$get_ids()
ctest_summary_df <- data.frame(
participant_id=p_ids,
mean_consistency_score=mean_cscores,
num_valid_graphemes=num_onlynonna
)
head(ctest_summary_df)
#> participant_id mean_consistency_score num_valid_graphemes
#> 1 1 131.2060 3
#> 2 2 101.3738 3
#> 3 3 151.9597 3Mean color response
It’s sometimes useful to calculate participants’ mean color responses. For instance, if using the color space CIELUV, the mean ‘L’ value indicates if a participant tended to use lighter or darker colors. The mean ‘u’ and ‘v’ values can be useful for calculating the average chroma, hue and saturation values.
participant level: get_participant_mean_color
This method returns a 3-element numeric vector that represents the participant’s mean response color value for color axis 1, 2 and 3, respectively. E.g. if color space ‘sRGB’ was specified when creating the participantgroup object, the 1st value corresponds to axis ‘R’, 2nd value to axis ‘G’, and 3rd value to axis ‘B’.
(in the code example, the values correspond to axes ‘L’, ‘u’, ‘v’, as that color space was specified when creating the participantgroup earlier)
mean_color_vec_p2 <- pg$participants[['2']]$get_participant_mean_color(na.rm=TRUE)
mean_color_vec_p2
#> [1] 59.0451936 0.5155495 -57.1274761The participant’s mean response color, disregarding any invalid color
responses (na.rm=TRUE), had an ‘L’ value of 59, ‘u’ value
of 0.52 and ‘v’ value of -57.
The rest of the tutorial will focus only on participantgroup-level
methods. You can find more info about participant-level methods by
running help(Participant).
participantgroup level: get_mean_colors
The participantgroup method get_mean_colors produces a
data frame that holds each participant’s mean color response values,
where the columns represent chosen color space axis 1, 2, and 3,
respectively (e.g. ‘R’, ‘G’, ‘B’ if ‘sRGB’ was specified upon
participantgroup creation):
mean_colors_df <- pg$get_mean_colors(na.rm=TRUE)
mean_colors_df
#> color_axis_1_mean color_axis_2_mean color_axis_3_mean
#> 1 51.97727 -23.5237442 -41.054796
#> 2 59.04519 0.5155495 -57.127476
#> 3 55.78877 7.9126543 7.415495Since this example is based on a participantgroup created with color space ‘Luv’ specification, the columns correspond to CIELUV ‘L’, ‘u’ and ‘v’ axes.
There are various ways to combine the returned data frame with
participant ID’s, here’s one using the R built-in cbind
function:
mean_cscores <- pg$get_mean_consistency_scores()
num_onlynonna <- pg$get_numbers_all_colored_graphemes()
p_ids <- pg$get_ids()
ctest_summary_df <- data.frame(
participant_id=p_ids,
mean_consistency_score=mean_cscores,
num_valid_graphemes=num_onlynonna
)
mean_color_df <- pg$get_mean_colors(na.rm=TRUE)
ctest_summary_df <- cbind(ctest_summary_df, mean_color_df)
head(ctest_summary_df)
#> participant_id mean_consistency_score num_valid_graphemes color_axis_1_mean
#> 1 1 131.2060 3 51.97727
#> 2 2 101.3738 3 59.04519
#> 3 3 151.9597 3 55.78877
#> color_axis_2_mean color_axis_3_mean
#> 1 -23.5237442 -41.054796
#> 2 0.5155495 -57.127476
#> 3 7.9126543 7.415495Validating participant data
synr includes a unique procedure for validating participant data based on estimating how varied participants’ color responses are. Detailed information is available in the validation-focused online article. A very rough example and explanation follows.
participantgroup level:
check_valid_get_twcv_scores
The larger example data frame synr_exampledf_large (with
3 trials per grapheme) is used in this example:
pg_large <- create_participantgroup(
raw_df=synr_exampledf_large,
n_trials_per_grapheme=3,
id_col_name="participant_id",
symbol_col_name="trial_symbol",
color_col_name="response_color",
color_space_spec="Luv"
)
# see separate article for explanation of why 'set.seed' is called
set.seed(1)
# call validation method
val_df <- pg_large$check_valid_get_twcv_scores(
min_complete_graphemes = 5,
dbscan_eps = 20,
dbscan_min_pts = 4,
max_var_tight_cluster = 150,
max_prop_single_tight_cluster = 0.6,
safe_num_clusters = 3,
safe_twcv = 250,
complete_graphemes_only = TRUE,
symbol_filter = LETTERS
)
head(val_df)
#> valid reason_invalid twcv num_clusters
#> 1 TRUE 1077.9557 8
#> 2 FALSE hi_prop_tight_cluster 195.1215 2
#> 3 TRUE 1222.0226 5
#> 4 TRUE 1568.6686 5
#> 5 TRUE 3154.0720 4In the example, we basically ask synr to check for each participant if they have, looking at letters only:
- used at least 3 clearly discernible colors (e. g. ‘red’, ‘yellow’ and ‘blue’) or otherwise greatly varied their responses (e. g. used very different shades of ‘red’/‘red-orange’ and ‘yellow’/‘yellow-green’)
- given all non-NA color responses for at least 4 letters
- not answered with roughly the same color (say, ‘black’) for more than 60% of the trials
This method, unlike other ones we’ve seen, returns a data frame. Looking at it, we can see that all data sets except the second one were classified as valid. The second data set was classified as invalid due to ‘hi_prop_tight_cluster’, which means that the participant responded with roughly the same color for more than 60% of all letter trials. The ‘twcv’ column gives a summary statistic which roughly describes how much variation there was in the participant’s data. The ‘num_clusters’ column gives an estimate of about how many clearly discernible colors that the participant repeatedly used.
Combining the returned mean color response data frame with other extracted data can be done as follows:
val_id_df <- cbind(
participant_id=pg_large$get_ids(),
val_df
)
head(val_id_df)
#> participant_id valid reason_invalid twcv num_clusters
#> 1 partA TRUE 1077.9557 8
#> 2 partB FALSE hi_prop_tight_cluster 195.1215 2
#> 3 partC TRUE 1222.0226 5
#> 4 partD TRUE 1568.6686 5
#> 5 partE TRUE 3154.0720 4Again, please see the validation-focused article for more information.
Filtering data
Participants who have synesthetic associations might only have those
for some of the graphemes used in a test. For instance, a participant
might only have synesthetic associations for digits, but not letters,
even though both categories are included in the test. synr helps you
apply filters to calculate summary statistics for only a subset of
graphemes. Filters are applied by passing a character vector of
symbols/graphemes to the symbol_filter= argument, when
using participant-level or participantgroup-level methods for summary
statistics.
participantgroup level filtering
weekdays_filter <- c(
'Monday', 'Tuesday', 'Wednesday', 'Thursday',
'Friday', 'Saturday', 'Sunday'
)
# note that the 'large' example data (rolled up in 'pg_large')
# are used again here
cscores_weekdays <- pg_large$get_mean_consistency_scores(symbol_filter=weekdays_filter)
cscores_weekdays
#> [1] 256.61146 79.72227 63.34418 256.80966 32.72955The produced vector holds each participant’s (there are 5 participants in this case) mean consistency score, only taking data from trials that had a weekday grapheme into account.
Handling summary statistics efficiently
If calculating many statistics with synr, putting them into a single
data frame becomes unwieldy. It may help to separate different kinds of
summary statistics into different data frames. When data (produced by
synr or from other sources) need to be combined, data frames can be
combined with the R merge function. A simple example
follows:
pg <- create_participantgroup(
raw_df=synr_exampledf_large,
n_trials_per_grapheme=3,
id_col_name="participant_id",
symbol_col_name="trial_symbol",
color_col_name="response_color",
time_col_name="response_time",
color_space_spec="Luv"
)
# form first data frame, with consistency scores
mean_cscores <- pg$get_mean_consistency_scores()
p_ids <- pg$get_ids()
cons_df <- data.frame(
participant_id=p_ids,
mean_consistency_score=mean_cscores
)
# form second data frame, with validation-related information
val_df <- cbind(
participant_id=pg$get_ids(),
pg$check_valid_get_twcv_scores()
)
# combine the two data frames, by telling R to 'link them up'
# based on the 'participant_id' column
cons_val_df <- merge(cons_df, val_df, by='participant_id')
head(cons_val_df)
#> participant_id mean_consistency_score valid reason_invalid twcv
#> 1 partA 270.62529 TRUE 3649.047
#> 2 partB 50.55262 FALSE hi_prop_tight_cluster 770.760
#> 3 partC NA TRUE 531.202
#> 4 partD 271.88148 TRUE 4806.165
#> 5 partE NA TRUE 1702.389
#> num_clusters
#> 1 4
#> 2 4
#> 3 6
#> 4 3
#> 5 5They key is to make sure each separate data frame includes the
participant ID’s and then set by='participant_id' (or
whatever the data frames’ participant ID columns are named).
Visualizing participant data
It can often be helpful to get an overview of participants’ response colors and each grapheme’s consistency score. synr uses ggplot2 to achieve this.
Producing plots for immediate display
participant level plotting: get_plot
For details on how the get_plot method works, please
have a look at the documentation for the Participant class, by using
help(Participant). There, you can scroll down to the
description of get_plot, under “Methods”.
pg_large <- create_participantgroup(
raw_df=synr_exampledf_large,
n_trials_per_grapheme=3,
id_col_name="participant_id",
symbol_col_name="trial_symbol",
color_col_name="response_color",
color_space_spec="Luv"
)
# increase grapheme size and angle them slightly to make them easier to see,
# and only include digits and letters (excluding the weekday data in this
# example)
p6_plot <- pg_large$participants[['partA']]$get_plot(
grapheme_size=2.2,
grapheme_angle=30,
symbol_filter = c(0:9, LETTERS)
)
p6_plot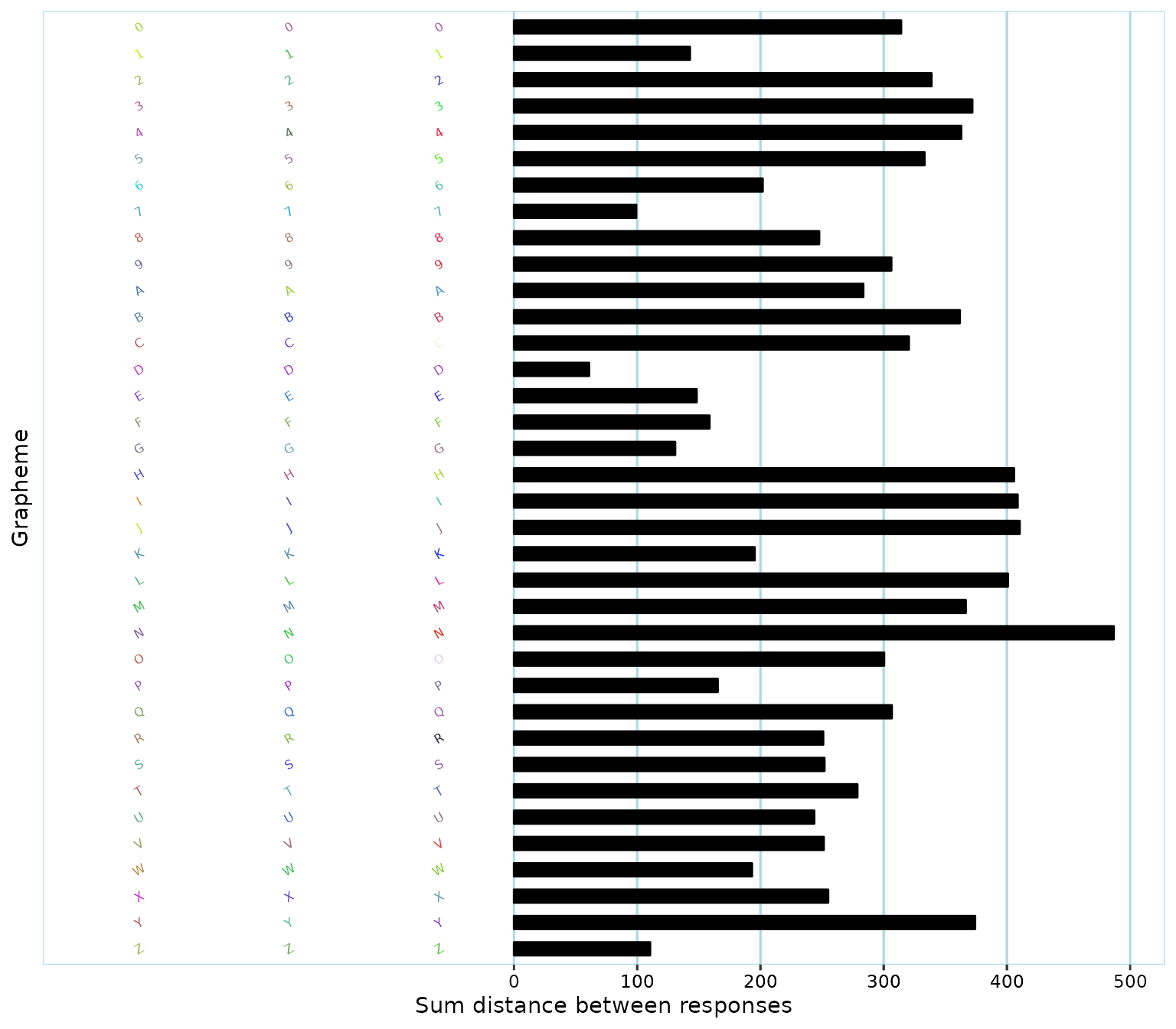
On the left side of the plot, you see the graphemes used in the test, colored in the participant’s response colors. The bars represent the consistency score for each grapheme.
Producing plots and saving them on your computer
participant level plot saving: save_plot
For details on how the save_plot method works, have a
look again at help(Participant). Scroll down to the
description of save_plot, under “Methods”. What is most
essential is that you specify the save_dir= argument, which
is where you want the plot to be saved (including filename at the
end):
pg_large$participants[[6]]$save_plot(
save_dir='path/to/save/folder/',
file_format='png',
grapheme_size=2.2,
grapheme_angle=30
)participantgroup level plot saving: save_plots
For details on how the save_plots method works, run
help(ParticipantGroup). Scroll down to the description of
save_plots, under “Methods”. What is most essential is
again that you specify the save_dir= argument, which is the
directory you want the plots to be saved to, and the
file_format= argument:
pg_large$save_plots(
save_dir='path/to/save/folder',
file_format='png',
grapheme_size=2.2,
grapheme_angle=30
)Next steps
There are additional articles which explain synr, including some mentioned throughout this article. To better understand how synr is used in practice, you might want to read Using synr with real data: Coloured vowels (online).
There is more detailed and technical information about synr that you can find in the help documentation, as mentioned throughout this article.